Бережливый ITSM – это комплекс мер и технических решений, предназначенных для повышения эффективности ITSM за счёт сокращения трудозатрат персонала Service Desk. Бережливый ITSM – это практическая реализация методологии Бережливого Производства (Lean Production) применительно к управлению ИТ-Услугами.
Бережливое Производство – это концепция менеджмента, основанная на неуклонном стремлении к устранению всех видов потерь. В соответствии с концепцией Бережливого Производства, всё, что потребляет ресурсы, но не создаёт (не добавляет) ценности для потребителя, является потерями и должно быть устранено. Ценность для потребителя — способность товара или услуги удовлетворять ожиданиям потребителя.
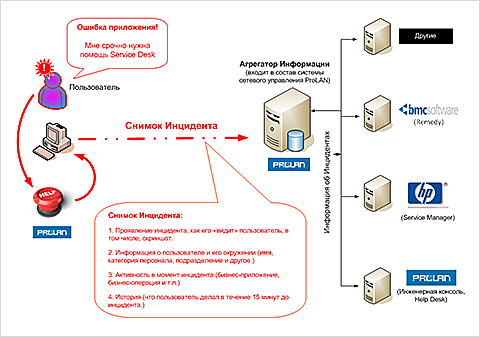
Рис.1.
Автоматическая передача Снимка Инцидента с использованием решения Красная Кнопка.
Внедрение Бережливого ITSM при помощи продуктов ProLAN позволяет сократить потребление наиболее дорогостоящего ресурса – времени.
| Методика | Продукт ProLAN | Решаемая задача |
| Автоматическое создание Снимка Инцидента | Красная Кнопка | Сокращение трудозатрат, связанных с квалификацией инцидентов |
| Объединение информации об инцидентах с информацией о здоровье ИТ-инфраструктуры и производительности бизнес-приложений | Красная Кнопка и Семейство ProLAN SLA-ON | Сокращение трудозатрат, связанных с диагностикой инцидентов |
| Мониторинг качества работы приложений «глазами пользователей» | Пятый Уровень | Сокращение числа инцидентов и повышение качества ИТ-услуг |
Автоматическое создание Снимка Инцидента позволяет Службе поддержки (Service Desk) автоматически получать информацию, достаточную для быстрой квалификации инцидентов
Обычно, чтобы сообщить службе Service Desk об инциденте, пользователю нужно позвонить по телефону, написать электронное письмо или заполнить web-форму. В каждом из этих случаев для квалификации инцидента полученной информации, как правило, бывает недостаточно. Поэтому оператор первой линии поддержки, получив сообщение об инциденте, обычно должен задать пользователю ряд уточняющих вопросов. Время, затрачиваемое на получение адекватных ответов, зависит от множества факторов, в частности, от коммуникативных навыков пользователя.
Трудозатраты первой линии поддержки могут быть существенно сокращены, если первая линия поддержки будет получать информацию, достаточную для квалификации инцидента, сразу, без необходимости задавать дополнительные вопросы. Примером такой информацией является Снимок Инцидента, автоматически создаваемый с помощью решения Красная Кнопка (рис.1).
На компьютерах пользователей устанавливается специальное ПО, позволяющее простым нажатием комбинации клавиш (нажатием Красной Кнопки) сообщать ИТ-Службе о сбоях в работе бизнес-приложений (ошибки, медленная работа и т.п.). При нажатии Красной Кнопки в службу Service Desk автоматически передаётся следующая информация:
Снимок Инцидента автоматически принимается Зондом, автоматически записывается в Консолидированную базу данных и автоматически отображается на Инженерной консоли. Зонд, Консолидированная база данных и Инженерная консоль являются компонентами Агрегатора Информации (подробнее ниже), входящего в состав продуктов семейства ProLAN SLA-ON.
На компьютере Агрегатора Информации также устанавливается Коннектор к Service Desk (Windows-сервис). Коннектор непрерывно сканирует Консолидированную базу данных на появление информации о новых инцидентах. Когда такая информация появляется, Коннектор выполняет следующее:
Автоматическое создание Снимка Инцидента позволяет существенно сократить трудозатраты на квалификацию и маршрутизацию инцидентов, а также снизить вероятность их ошибочной квалификации и маршрутизации. Это повышает эффективность ITSM. Подробнее см. Красная Кнопка.
Объединение информации об инцидентах, с информацией о здоровье ИТ-Инфраструктуры и производительности бизнес-приложений позволяет службе Service Desk быстро определять корневые причины сбоев в работе ИТ-Инфраструктуры и бизнес-приложений
Очевидно, что эффективность ITSM в значительной степени зависит от скорости, с которой ИТ-Служба диагностирует инциденты. Традиционная схема организации ITSM (рис. 2) не способствует быстрой диагностике инцидентов.
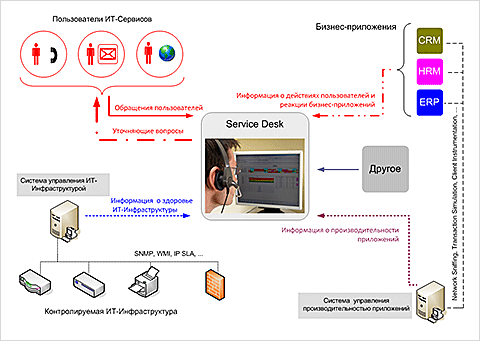
Рис.2.
Традиционная схема организации ITSM
Причина в том, что инциденты и информация, характеризующая работу ИТ-Инфраструктуры и бизнес-приложений, не «связаны» друг с другом. Инциденты регистрируются в Service Desk, а метрики, характеризующие здоровье ИТ-Инфраструктуры и производительность приложений измеряются с помощью других систем. В таком случае, чтобы диагностировать инцидент, обычно нужно сделать следующее.
Сначала нужно определить время, когда произошёл сбой (инцидент). Затем, зная время, проанализировать метрик здоровья ИТ-Инфраструктуры и производительности приложений в этот момент времени. Поскольку инциденты регистрируются, как правило, по телефону, установить точное время бывает сложно, поэтому нужно анализировать метрики на большом временном интервале. Поскольку данных много, «увидеть» таким способом корневую причину удаётся не всегда. В таком случае единственным выходом является попытаться воспроизвести сбой. Как правило, это очень трудоёмкая задача. По информации компании Network Instruments, 59% из 592 опрошенных этой компанией сетевых профессионалов, на воспроизведение сбоев тратят не менее 25 дней в год, а 71% опрошенных тратят 25 и более дней в год ещё и на определение причин сбоев, которые они воспроизвели (подробнее).
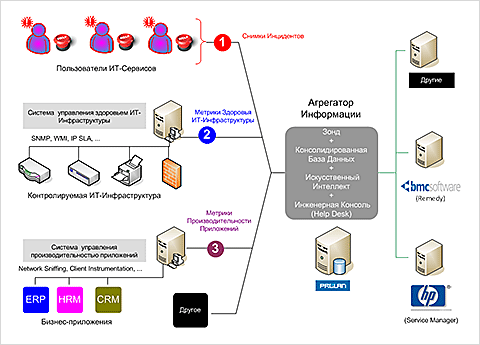
Рис.3.
Схема Бережливого ITSM
Время диагностики инцидентов можно существенно сократить, если придерживаться следующих правил:
Схема организации ITSM, обеспечивающая поддержку приведенных выше правил, показана на рис.3. Ключевой элемент предлагаемой схемы – Агрегатор Информации. Агрегатор включает в себя: Зонд, Консолидированную базу данных, Искусственный Интеллект, Инженерную консоль. Зонд принимает Снимки Инцидентов, собирает информацию о здоровье ИТ-Инфраструктуры и производительности бизнес-приложений, и всю полученную информацию записывает в Консолидированную базу данных. Искусственный Интеллект обрабатывает консолидированную информацию по заданным правилам, и после обработки передаёт в Service Desk.
По сравнению с традиционной схемой организации ITSM, предлагаемая схема имеет два важных преимущества. Во-первых, Service Desk получает не «сырую», а обработанную информацию, позволяющую быстро «ставить диагноз» инцидентам. Например, сразу виден масштаб бедствия (единичный пользователь, группа пользователей определённого региона, группа пользователей определённого бизнес-приложения и т.п.), сразу видно, что могло привести к возникновению инцидента (какие действия пользователя предшествовали инциденту) и многое другое. Второе преимущество, - возможность быстро определять причинно-следственные связи между инцидентами, с одной стороны, и здоровьем ИТ-Инфраструктуры и производительностью бизнес-приложений, с другой стороны. Для решения этой задачи используется Инженерная консоль, позволяющая отображать всю получаемую информацию с «привязкой» к единой временной шкале. Это очень действенный метод определения корневых причин инцидентов (root cause analysis).
Мониторинг качества работы приложений «глазами пользователей» позволяет обнаруживать сбои в работе приложений до обращения пользователей в Service Desk и, таким образом, существенно сократить число инцидентов и повысить качество ИТ-Услуг.
Мониторинг качества работы приложений «глазами пользователей» (далее – Мониторинг Quality of Experience, QoE) – это получение в режиме реального времени информации о качестве работы реальных бизнес-приложений у реальных пользователей. Основной целью такого мониторинга является обнаружение сбоев в работе ИТ-Инфраструктуры и бизнес-приложений до обращения пользователей в Service Desk. Другими словами, чтобы узнавать о качестве работы ИТ-Сервисов не по числу обращений в Service Desk, а независимо от этого. Мониторинг QoE позволяет снизить число обращений в Service Desk (читай - трудозатраты персонала ИТ-Службы), и повысить лояльность пользователей ИТ-Сервисов.
Примером решения, предназначенного для Мониторинга QoE, является решение Пятый Уровень компании ProLAN. Внедрив данное решение, ИТ-Служба сможет автоматически получать следующую информацию:
Для измерения QoE используется метод Client Instrumentation и Windows-приложение EPM-Agent Plus (функционал HelpMe). Программа устанавливается на компьютерах пользователей; если пользователи работают в терминальном режиме, то на терминальном сервере. Принцип работы Агента EPM-Agent Plus заключается в автоматическом отслеживании всех выполняемых на компьютере пользователя процессов и связанных с ними событий.
Пятый Уровень имеет ряд преимуществ по сравнению с аналогичными решениями западных компаний. Во-первых, - высокая экономичность. Стоимость Пятого Уровня как минимум на порядок ниже стоимости западных аналогов. Во-вторых, - поддержка бизнес-приложений российского производства. Западные продукты, как правило, «не понимают» российские бизнес-приложения. Третье преимущество - прозрачная интеграция с системами сетевого управления. Очень немногие западные продукты сегодня умеют это делать. Всё это, безусловно, очень важно, но есть еще два преимущества, о которых следует сказать особо. Это поддержка Агентом EPM-Agent Plus протокола SNMP и прозрачная интеграция Пятого Уровня с решением Красная Кнопка.
Поддержка Агентом EPM-Agent Plus протокола SNMP – это возможность передачи Агентом EPM-Agent Plus всех измеряемых им метрик с использованием протокола SNMP (рис.4).
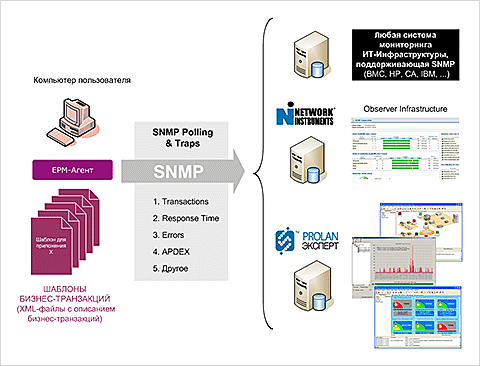
Рис.4.
Поддержка Агентом EPM-Agent Plus протокола SNMP
Поддержка Агентом EPM-Agent Plus протокола SNMP означает возможность использования в качестве Консоли управления QoE практически любой системы сетевого управления, т.к. практически любая система сетевого управления сегодня поддерживает SNMP.
Интеграция Пятого Уровня с Красной Кнопкой обеспечивает возможность автоматической передачи в Service Desk Снимков Инцидента по инициативе Агента EPM-Agent Plus. Другими словами, в этом случае Красную Кнопку «нажимает» не пользователь, а Агент EPM-Agent Plus, (рис.5).
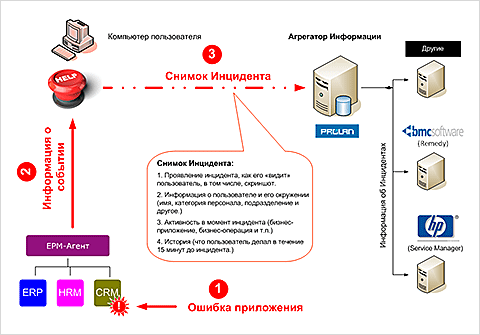
Рис.5.
Автоматическая передача Снимка Инцидента по инициативе Агента EPM-Agent Plus
Предположим, бизнес-приложение на компьютере пользователя выдало сообщение об ошибке. Установленный на компьютере пользователя Агент EPM-Agent Plus автоматически идентифицирует возникшую ошибку и автоматически информирует об этом событии Красную Кнопку (функционал HelpMe). При этом Агент EPM-Agent Plus передаст Красной Кнопке подробное описание данного события. Получив информацию о событии, Красная Кнопка сделает снимок экрана (если для данного события это разрешено), прочитает переменные среды, определит выполняемую бизнес-операцию и т.д., после чего передаст всю полученную информацию в Агрегатор Информации, откуда она будет автоматически передана в Service Desk.
Интеграция Пятого Уровня с Красной Кнопкой обеспечивает принципиально новый уровень Мониторинга QoE. Новизна заключается в следующем:


 Навигация по разделу
Навигация по разделу